优雅退出
这一篇是为了解决引入buffer后,如何保证数据不丢失?
简单介绍一下问题,如下图,通过open api传入的message会在buffer中囤积到一定量后进行处理,引入buffer是为了减少mysql的压力,减少对于数据库的频繁读写。但是由于buffer是内存中的一个数据结构,那么如何保证数据不丢失呢?
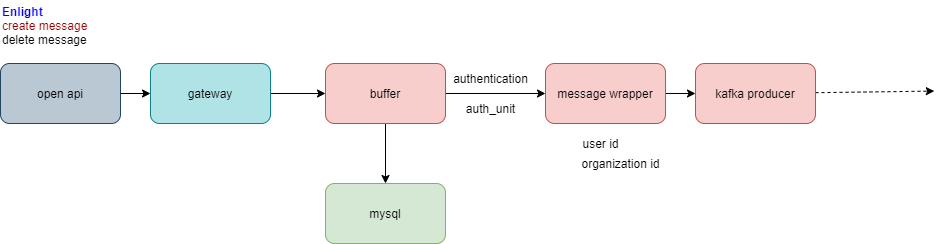
数据丢失的情况可能发生于:(1)升级部署时;(2)pod重启时;(3)极端情况,如断电等。
在公有云情况下,可以先忽略极端情况,云服务商会有一定的保障策略。因此只需要把目光聚集到(1)和(2)两点。 其实可以业界有很多可以参考的例子,比如mysql的redo log和redis的aof都可以一定程度保证在发生问题的时候数据的完整性,但是如果在我们的服务中实现这样的东西太重了,个人认为其实保障数据完整性是一个很通用的需求,应该会有一些开源的项目支持(但是没有找到,不过我认为这是一个赚star的好机会)。
回到主要问题,考虑到我们的服务都是java的服务,有一种简单的方法可以实现在应用退出的时候优雅停机:使用java提供的shutdown hook来做这个事情(在spring boot中也有类似的东西,通过@PreDestroy注解来实现,不过追到底还是shutdown hook),当jvm收到退出的信号时,调用shutdown hook内的方法,完成清理操作。
shutdown hook可以保证在应用主动关闭、代码中调用System#exit、OOM、终端Ctrl+C等情况下被调用,对于我们看重的(1)(2)来说,可以很好的解决问题,举个例子增加如下hook:
Runtime.getRuntime().addShutdownHook(new Thread(() -> System.out.println(“shutdown hook!"))); 在退出时会在终端打印出 “shutdown hook!"。在实际使用中,可以对将对buffer清理的动作加到hook中,于是可以保证优雅退出。
可是,这样就完了吗?
在kubernetes中优雅停机
在本地java -jar xxx.jar运行一个java程序后,通过kill pid这种方式可以完美实现优雅退出,但是到了ecp上,情况并不是这么回事。在每次重新部署的时候,发现并没有触发shutdown hook,问题出在哪里呢?
这个要从kubernetes中pod关闭说起,参照 https://kubernetes.io/docs/concepts/workloads/pods/pod/#termination-of-pods
- User sends command to delete Pod, with default grace period (30s)
- The Pod in the API server is updated with the time beyond which the Pod is considered “dead” along with the grace period.
- Pod shows up as “Terminating” when listed in client commands
- (simultaneous with 3) When the Kubelet sees that a Pod has been marked as terminating because the time in 2 has been set, it begins the Pod shutdown process. a. If one of the Pod’s containers has defined a preStop hook, it is invoked inside of the container. If the preStop hook is still running after the grace period expires, step 2 is then invoked with a small (2 second) one-time extended grace period. You must modify terminationGracePeriodSeconds if the preStop hook needs longer to complete. b. The container is sent the TERM signal. Note that not all containers in the Pod will receive the TERM signal at the same time and may each require a preStop hook if the order in which they shut down matters.
- (simultaneous with 3) Pod is removed from endpoints list for service, and are no longer considered part of the set of running Pods for replication controllers. Pods that shutdown slowly cannot continue to serve traffic as load balancers (like the service proxy) remove them from their rotations.
- When the grace period expires, any processes still running in the Pod are killed with SIGKILL.
- The Kubelet will finish deleting the Pod on the API server by setting grace period 0 (immediate deletion). The Pod disappears from the API and is no longer visible from the client.
这里4.a中提到的preStop hook先不去管他,这是kubernetes提供的一种优雅停机方式。可以看到在4.b中,container会被发送TERM signal,而按照常理来说,如果我们的java进程收到这个TERM信号,那么就会优雅退出,shutdown hook就会执行。可是现实并没有按照我们想要的进行流转,问题就出在这个TERM信号这里。
ENTRYPOINT中的startup.sh
仔细查看我们的Dockerfile,大概的样式如下:
#Dockerfile
...
ENTRYPOINT ["bash","./startup.sh"]
#startup.sh
...
nohup java $JAVA_OPTS -jar ./xxx.jar --server.port=8080 &
while true
do
sleep 2
done
这样做的问题是什么呢?
可以先看一个例子,在容器中,输入ps -ef可以得到
[root@xxx-74bc7c554d-vvz4w envuser]# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 Jul15 ? 00:00:32 bash ./startup.sh
root 10 1 4 Jul15 ? 02:19:06 java -Xmx3072m,output=tcpse
root 94141 0 1 02:55 pts/0 00:00:00 bash
root 94157 1 0 02:55 ? 00:00:00 sleep 2
root 94158 94141 0 02:55 pts/0 00:00:00 ps -ef
可以看到,1号进程是我们的bash ./startup.sh,而10号进程是真正服务所在的java进程,并且他是1号进程的子进程。问题就在这里,在pod关闭时,TERM信号只会发送给1号进程,而1号进程并不会将此TERM信号转发到下面的子进程,由此java进程收不到TERM信号,那么也就无法触发shutdown hook,无法优雅退出(最终应该时通过kill -9 pid这种方式退出的)。
那么现在的问题就在于如何将TERM信号传到java进程上,有两种方法:
第一种,使用在startup.sh中,使用下面的方式启动java进程,这里exec的作用是使java进程取代当前的bash进程作为1号进程,那么当TERM信号发送给1号进程的时候自然能够优雅退出。但是,这会带来一些问题,我们后面再说。
#startup.sh
...
exec java $JAVA_OPTS -jar ./xxx.jar --server.port=8080
第二种,也是推荐的一种,在startup.sh中利用trap捕获TERM信号,将其传递给下面的子进程,如下所示,至于为什么这么写,有一篇很好的参考文献 http://veithen.io/2014/11/16/sigterm-propagation.html:
#startup.sh
...
trap 'kill -TERM $child' TERM
nohup java $JAVA_OPTS -jar ./xxx.jar --server.port=8080 &
child=$!
wait $child
wait $child
为什么不推荐java进程作为1号进程
上面的两种方式里,说到了不推荐第一种方式,为什么呢?
这要涉及到unix系统中1号进程的特殊作用:1号进程会作为孤儿进程的父进程,同时会需要有收割清理的功能,避免系统产生僵尸进程。对于bash来说,比较完备了,可以很好的adop and reap,然而对于用户写的java进程来说,一般不会考虑到收割清理这种功能,所以如果将java进程作为1号进程的话,容易产生僵尸进程。
举个例子:
java (1) -> A process (10),代表10号进程A process是1号java进程的子进程,当A process 终结的时候,会发送SIGCHILD信号唤醒java进程,期待其进行收割。但是假如java进程没有特殊的处理然后不理会这个信号,那么A process将会成为一个zombie process,即虽然已经终结了,但是依然占据一部分资源,这不是我们所希望看到的。
因此,推荐使用第二种方式,将bash作为1号进程,这样不必担心zombie process的问题。
这里再推荐一篇极佳的参考 https://blog.phusion.nl/2015/01/20/docker-and-the-pid-1-zombie-reaping-problem/, 极力推荐大家读一读。
最后再说一下while loop的问题
在前面之前的startup.sh里面,可以看到最后面有一个while循环,有没有想过为什么要加这个东西?
其实根源在于它的上一句通过nohup … &的方式启动了java进程,如果不在最后进行loop,那么startup.sh就会执行完毕而退出,带来的问题就是pod的状态变为completed的状态,也就是说pod认为任务已经执行完毕而自动退出了。作为一个web server端来说,肯定不能让他退出啊,所以在这里采用了while循环来阻止进程退出。不过这是历史问题了,在第二种startup.sh中,trap wait机制会阻塞进程直到子进程退出,因此后面也就不需要while loop这种东西了。最后再留个问题,为什么要两遍wait $child ?那篇参考文献中讲的很详细了 : )